





We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we introduce a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches.
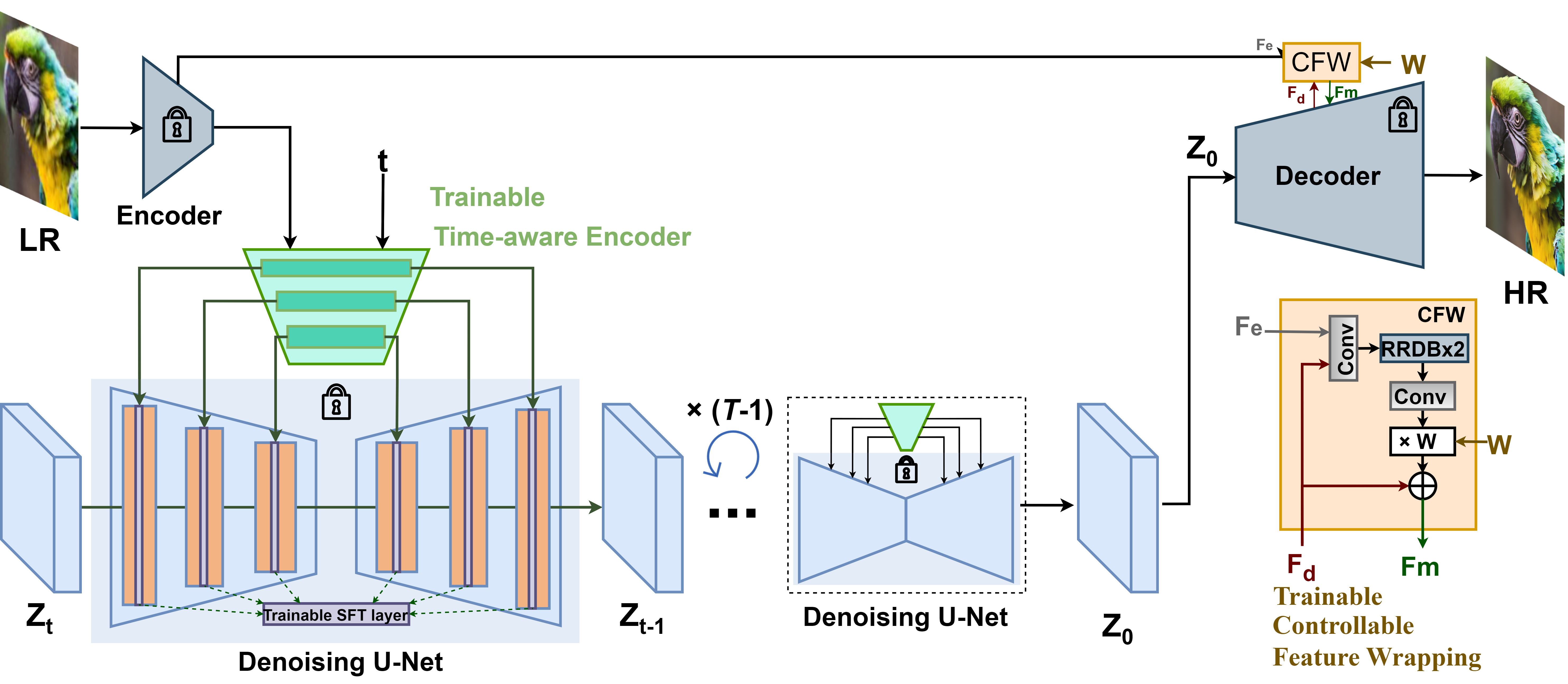
We first finetune the time-aware encoder that is attached to a fixed pre-trained Stable Diffusion model. Features are combined with trainable spatial feature transform (SFT) layers. Such a simple yet effective design is capable of leveraging rich diffusion prior for image SR. Then, the diffusion model is fixed. Inspired by CodeFormer, we introduce a controllable feature wrapping (CFW) module to obtain a tuned feature in a residual manner, given the additional information from LR features and features from the fixed decoder of autoencoder. With an adjustable coefficient, CFW can trade between quality and fidelity. We further enable arbitrary-size super-resolution by applying an aggregation sampling strategy.

@article{wang2024exploiting,
author = {Wang, Jianyi and Yue, Zongsheng and Zhou, Shangchen and Chan, Kelvin C.K. and Loy, Chen Change},
title = {Exploiting Diffusion Prior for Real-World Image Super-Resolution},
article = {International Journal of Computer Vision},
year = {2024}
}